05. 图的拓扑排序知识
05. 图的拓扑排序知识
1. 拓扑排序简介
拓扑排序(Topological Sorting):一种对有向无环图(DAG)的所有顶点进行线性排序的方法,使得图中任意一点
和 ,如果存在有向边 ,则 必须在 之前出现。对有向图进行拓扑排序产生的线性序列称为满足拓扑次序的序列,简称拓扑排序。
图的拓扑排序是针对有向无环图(DAG)来说的,无向图和有向有环图没有拓扑排序,或者说不存在拓扑排序。
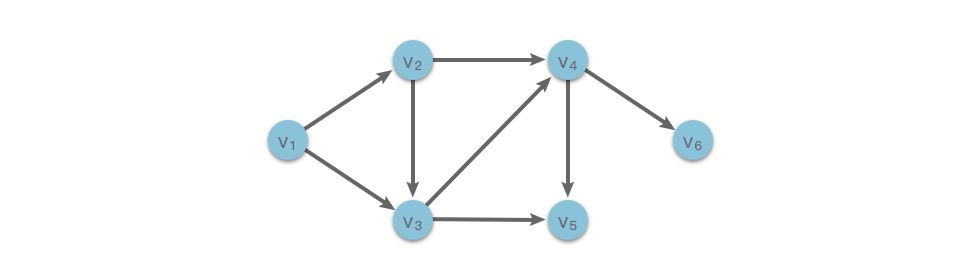
如上图中的有向无环图(DAG)所示,
2. 拓扑排序的实现方法
拓扑排序有两种实现方法,分别是「Kahn 算法」和「DFS 深度优先搜索算法」。接下来我们依次来看下它们是如何实现的。
2.1 Kahn 算法
Kahn 算法的基本思想:
- 不断找寻有向图中入度为
的顶点,将其输出。 - 然后删除入度为
的顶点和从该顶点出发的有向边。 - 重复上述操作直到图为空,或者找不到入度为
的节点为止。
2.1.1 Kahn 算法的实现步骤
- 使用数组
- 维护一个入度为
- 每次从集合中选择任何一个没有前驱(即入度为
- 从图中删除该顶点
- 重复上述过程,直到集合
- 如果不存在环路,则
2.1.2 Kahn 算法的实现代码
import collections
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingKahn(self, graph: dict):
indegrees = {u: 0 for u in graph} # indegrees 用于记录所有顶点入度
for u in graph:
for v in graph[u]:
indegrees[v] += 1 # 统计所有顶点入度
# 将入度为 0 的顶点存入集合 S 中
S = collections.deque([u for u in indegrees if indegrees[u] == 0])
order = [] # order 用于存储拓扑序列
while S:
u = S.pop() # 从集合中选择一个没有前驱的顶点 0
order.append(u) # 将其输出到拓扑序列 order 中
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
indegrees[v] -= 1 # 删除从顶点 u 出发的有向边
if indegrees[v] == 0: # 如果删除该边后顶点 v 的入度变为 0
S.append(v) # 将其放入集合 S 中
if len(indegrees) != len(order): # 还有顶点未遍历(存在环),无法构成拓扑序列
return []
return order # 返回拓扑序列
def findOrder(self, n: int, edges):
# 构建图
graph = dict()
for i in range(n):
graph[i] = []
for u, v in edges:
graph[u].append(v)
return self.topologicalSortingKahn(graph)2.2 基于 DFS 实现拓扑排序算法
基于 DFS 实现拓扑排序算法的基本思想:
- 对于一个顶点
,深度优先遍历从该顶点出发的有向边 。如果从该顶点 出发的所有相邻顶点 都已经搜索完毕,则回溯到顶点 时,该顶点 应该位于其所有相邻顶点 的前面(拓扑序列中)。 - 这样一来,当我们对每个顶点进行深度优先搜索,在回溯到该顶点时将其放入栈中,则最终从栈顶到栈底的序列就是一种拓扑排序。
2.2.1 基于 DFS 实现拓扑排序算法实现步骤
使用集合
使用集合
使用布尔变量
从任意一个未被访问的顶点
- 如果顶点
- 如果当前顶点被访问或者有环时,则无需再继续遍历,直接返回。
- 如果顶点
将顶点
当顶点
取消本次深度优先搜索时,顶点
对其他未被访问的顶点重复
如果不存在环路,则将
2.2.2 DFS 深度优先搜索算法实现代码
import collections
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingDFS(self, graph: dict):
visited = set() # 记录当前顶点是否被访问过
onStack = set() # 记录同一次深搜时,当前顶点是否被访问过
order = [] # 用于存储拓扑序列
hasCycle = False # 用于判断是否存在环
def dfs(u):
nonlocal hasCycle
if u in onStack: # 同一次深度优先搜索时,当前顶点被访问过,说明存在环
hasCycle = True
if u in visited or hasCycle: # 当前节点被访问或者有环时直接返回
return
visited.add(u) # 标记节点被访问
onStack.add(u) # 标记本次深搜时,当前顶点被访问
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
dfs(v) # 递归访问节点 v
order.append(u) # 后序遍历顺序访问节点 u
onStack.remove(u) # 取消本次深搜时的 顶点访问标记
for u in graph:
if u not in visited:
dfs(u) # 递归遍历未访问节点 u
if hasCycle: # 判断是否存在环
return [] # 存在环,无法构成拓扑序列
order.reverse() # 将后序遍历转为拓扑排序顺序
return order # 返回拓扑序列
def findOrder(self, n: int, edges):
# 构建图
graph = dict()
for i in range(n):
graph[i] = []
for v, u in edges:
graph[u].append(v)
return self.topologicalSortingDFS(graph)3. 拓扑排序的应用
拓扑排序可以用来解决一些依赖关系的问题,比如项目的执行顺序,课程的选修顺序等。
3.1 课程表 II
3.1.1 题目链接
3.1.2 题目大意
描述:给定一个整数
要求:返回学完所有课程所安排的学习顺序。如果有多个正确的顺序,只要返回其中一种即可。如果无法完成所有课程,则返回空数组。
说明:
- 所有
示例:
- 示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:[0,1]
解释:总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1]。- 示例 2:
输入:numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]]
输出:[0,2,1,3]
解释:总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。
因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3]。3.1.3 解题思路
思路 1:拓扑排序
这道题是「0207. 课程表」的升级版,只需要在上一题的基础上增加一个答案数组
- 使用哈希表
- 借助队列
- 从队列中选择一个节点
- 从图中删除该顶点
- 重复上述步骤
- 最后判断总的顶点数和拓扑序列中的顶点数是否相等,如果相等,则返回答案数组
思路 1:代码
import collections
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingKahn(self, graph: dict):
indegrees = {u: 0 for u in graph} # indegrees 用于记录所有顶点入度
for u in graph:
for v in graph[u]:
indegrees[v] += 1 # 统计所有顶点入度
# 将入度为 0 的顶点存入集合 S 中
S = collections.deque([u for u in indegrees if indegrees[u] == 0])
order = [] # order 用于存储拓扑序列
while S:
u = S.pop() # 从集合中选择一个没有前驱的顶点 0
order.append(u) # 将其输出到拓扑序列 order 中
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
indegrees[v] -= 1 # 删除从顶点 u 出发的有向边
if indegrees[v] == 0: # 如果删除该边后顶点 v 的入度变为 0
S.append(v) # 将其放入集合 S 中
if len(indegrees) != len(order): # 还有顶点未遍历(存在环),无法构成拓扑序列
return []
return order # 返回拓扑序列
def findOrder(self, numCourses: int, prerequisites):
graph = dict()
for i in range(numCourses):
graph[i] = []
for v, u in prerequisites:
graph[u].append(v)
return self.topologicalSortingKahn(graph)思路 1:复杂度分析
- 时间复杂度:
- 空间复杂度:
3.2 找到最终的安全状态
3.2.1 题目链接
3.2.2 题目大意
描述:给定一个有向图
要求:找出图中所有的安全节点,将其存入数组作为答案返回,答案数组中的元素应当按升序排列。
说明:
- 终端节点:如果一个节点没有连出的有向边,则它是终端节点。或者说,如果没有出边,则节点为终端节点。
- 安全节点:如果从该节点开始的所有可能路径都通向终端节点,则该节点为安全节点。
- 图中可能包含自环。
- 图中边的数目在范围
示例:
- 示例 1:
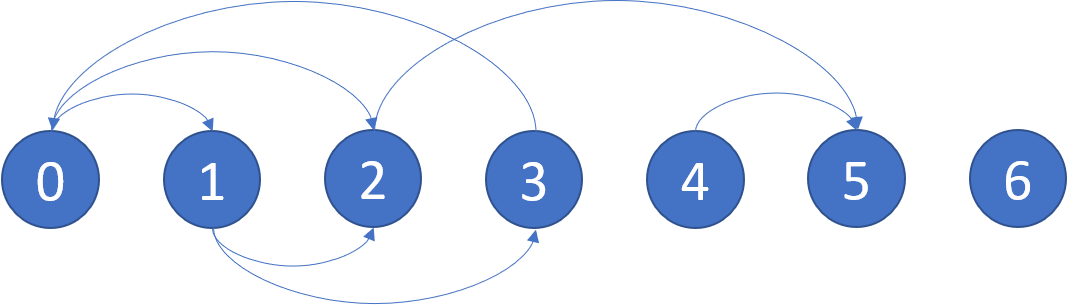
输入:graph = [[1,2],[2,3],[5],[0],[5],[],[]]
输出:[2,4,5,6]
解释:示意图如上。
节点 5 和节点 6 是终端节点,因为它们都没有出边。
从节点 2、4、5 和 6 开始的所有路径都指向节点 5 或 6。- 示例 2:
输入:graph = [[1,2,3,4],[1,2],[3,4],[0,4],[]]
输出:[4]
解释:
只有节点 4 是终端节点,从节点 4 开始的所有路径都通向节点 4。3.2.3 解题思路
思路 1:拓扑排序
- 根据题意可知,安全节点所对应的终点,一定是出度为
- 我们可以利用拓扑排序来判断顶点是否在环中。
- 为了找出安全节点,可以采取逆序建图的方式,将所有边进行反向。这样出度为
- 然后通过拓扑排序不断移除入度为
- 最后将所有安全的起始节点存入数组作为答案返回。
思路 1:代码
class Solution:
# 拓扑排序,graph 中包含所有顶点的有向边关系(包括无边顶点)
def topologicalSortingKahn(self, graph: dict):
indegrees = {u: 0 for u in graph} # indegrees 用于记录所有节点入度
for u in graph:
for v in graph[u]:
indegrees[v] += 1 # 统计所有节点入度
# 将入度为 0 的顶点存入集合 S 中
S = collections.deque([u for u in indegrees if indegrees[u] == 0])
while S:
u = S.pop() # 从集合中选择一个没有前驱的顶点 0
for v in graph[u]: # 遍历顶点 u 的邻接顶点 v
indegrees[v] -= 1 # 删除从顶点 u 出发的有向边
if indegrees[v] == 0: # 如果删除该边后顶点 v 的入度变为 0
S.append(v) # 将其放入集合 S 中
res = []
for u in indegrees:
if indegrees[u] == 0:
res.append(u)
return res
def eventualSafeNodes(self, graph: List[List[int]]) -> List[int]:
graph_dict = {u: [] for u in range(len(graph))}
for u in range(len(graph)):
for v in graph[u]:
graph_dict[v].append(u) # 逆序建图
return self.topologicalSortingKahn(graph_dict)思路 1:复杂度分析
- 时间复杂度:
- 空间复杂度:
来源:https://github.com/itcharge/LeetCode-Py