30.Spring Boot Elasticsearch 入门
30.Spring Boot Elasticsearch 入门
1. 概述
如果胖友之前有用过 Elasticsearch 的话,可能有过被使用的 Elasticsearch 客户端版本搞死搞活。如果有,那么一起握个抓。所以,我们在文章的开始,先一起理一理这块。
Elasticsearch(ES)提供了两种连接方式:
transport :通过 TCP 方式访问 ES 。
rest :通过 HTTP API 方式访问 ES 。
对应的库是:
elasticsearch-rest-client+org.elasticsearch.client.rest,提供 low-level rest API 。elasticsearch-rest-high-level-client,提供 high-level rest API 。从 Elasticsearch 6.0.0-beta1 开始提供。
如果想进一步了解上述的 3 个 ES 客户端,可以看看 《Elasticsearch 客户端 transport vs rest》 文章。
虽然说,ES 提供了 2 种方式,官方目前建议使用 rest 方式,而不是 transport 方式。并且,transport 在未来的计划中,准备废弃 。并且,阿里云提供的 Elasticsearch 更加干脆,直接只提供 rest 方式,而不提供 transport 方式。
在社区中,有个 Jest 开源项目,也提供了的 Elasticsearch REST API 客户端。
Elasticsearch 5.0 才有了自己的 Rest 客户端 ,6.0 才有了更好用的客户端,所以 Jest 作为第三方客户端,使用非常广泛。
正如我们在项目中,编写数据库操作的逻辑,使用 MyBatis 或者 JPA 为主,而不使用原生的 JDBC 。那么,我们在编写 Elasticsearch 操作的逻辑,也不直接使用上述的客户端,而是:
spring-data-elasticsearch,基于 Elasticsearch transport 客户端封装。spring-data-jest,基于 Jest 客户端封装。
虽然这两者底层使用的不同客户端,但是都基于 Spring Data 体系,所以项目在使用时,编写的代码是相同的。也因此,如果胖友想从 spring-data-elasticsearch 迁移到 spring-data-jest 时,基本透明无成本
下面,我们分别来入门:
- Spring Data Jest
- Spring Data Elasticsearch
艿艿:如果胖友还没安装 Elasticsearch ,并安装 IK 插件,可以参考下 《Elasticsearch 极简入门》 文章,先进行下安装。
2. Spring Data Jest
示例代码对应仓库:lab-15-spring-data-jest 。
- ES 版本号:6.5.0
spring-boot-starter-data-jest:3.2.5.RELEASE
本小节,我们会使用 spring-boot-starter-data-jest 自动化配置 Spring Data Jest 主要配置。同时,编写相应的 Elasticsearch 的 CRUD 操作。
2.1 引入依赖
在 pom.xml 文件中,引入相关依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>lab-15-spring-data-jest</artifactId>
<dependencies>
<!-- 自动化配置 Spring Data Jest -->
<dependency>
<groupId>com.github.vanroy</groupId>
<artifactId>spring-boot-starter-data-jest</artifactId>
<version>3.2.5.RELEASE</version>
</dependency>
<!-- 方便等会写单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>2.2 Application
创建 Application.java 类,配置 @SpringBootApplication 注解即可。代码如下:
// Application.java
@SpringBootApplication(exclude = {ElasticsearchAutoConfiguration.class, ElasticsearchDataAutoConfiguration.class})
public class Application {
}- 需要排除 ElasticsearchAutoConfiguration 和 ElasticsearchDataAutoConfiguration 自动配置类,否则会自动配置 Spring Data Elasticsearch 。
2.3 配置文件
在 application.yml 中,添加 Jest 配置,如下:
spring:
data:
# Jest 配置项
jest:
uri: http://127.0.0.1:9200- 我们使用本地的 ES 服务。默认情况下,ES rest 连接方式暴露的端口是 9200 。
2.4 ESProductDO
在 cn.iocoder.springboot.lab15.springdatajest.dataobject 包路径下,创建 ESProductDO 类。代码如下:
// ESProductDO.java
@Document(indexName = "product", // 索引名
type = "product", // 类型。未来的版本即将废弃
shards = 1, // 默认索引分区数
replicas = 0, // 每个分区的备份数
refreshInterval = "-1" // 刷新间隔
)
public class ESProductDO {
/**
* ID 主键
*/
@Id
private Integer id;
/**
* SPU 名字
*/
@Field(analyzer = FieldAnalyzer.IK_MAX_WORD, type = FieldType.Text)
private String name;
/**
* 卖点
*/
@Field(analyzer = FieldAnalyzer.IK_MAX_WORD, type = FieldType.Text)
private String sellPoint;
/**
* 描述
*/
@Field(analyzer = FieldAnalyzer.IK_MAX_WORD, type = FieldType.Text)
private String description;
/**
* 分类编号
*/
private Integer cid;
/**
* 分类名
*/
@Field(analyzer = FieldAnalyzer.IK_MAX_WORD, type = FieldType.Text)
private String categoryName;
// 省略 setting/getting 方法
}为了区别关系数据库的实体对象,艿艿习惯以 ES 前缀开头。
字段上的
@Field注解的 FieldAnalyzer ,是定义的枚举类,记得自己创建下噢。代码如下:
// FieldAnalyzer.java
public class FieldAnalyzer {
/**
* IK 最大化分词
*
* 会将文本做最细粒度的拆分
*/
public static final String IK_MAX_WORD = "ik_max_word";
/**
* IK 智能分词
*
* 会做最粗粒度的拆分
*/
public static final String IK_SMART = "ik_smart";
}- 再友情提示下,一定要记得给 Elasticsearch 安装 IK 插件,不然等会示例会报错的哟。
2.5 ProductRepository
在 cn.iocoder.springboot.lab15.mybatis.repository 包路径下,创建 ProductRepository 接口。代码如下:
// ProductRepository.java
public interface ProductRepository extends ElasticsearchRepository<ESProductDO, Integer> {
}- 继承
org.springframework.data.elasticsearch.repository.ProductRepository接口,第一个泛型设置对应的实体是 ESProductDO ,第二个泛型设置对应的主键类型是 Integer 。 - 因为实现了 ElasticsearchRepository 接口,Spring Data Jest 会自动生成对应的 CRUD 等等的代码。😈 是不是很方便。
- ElasticsearchRepository 类图如下:
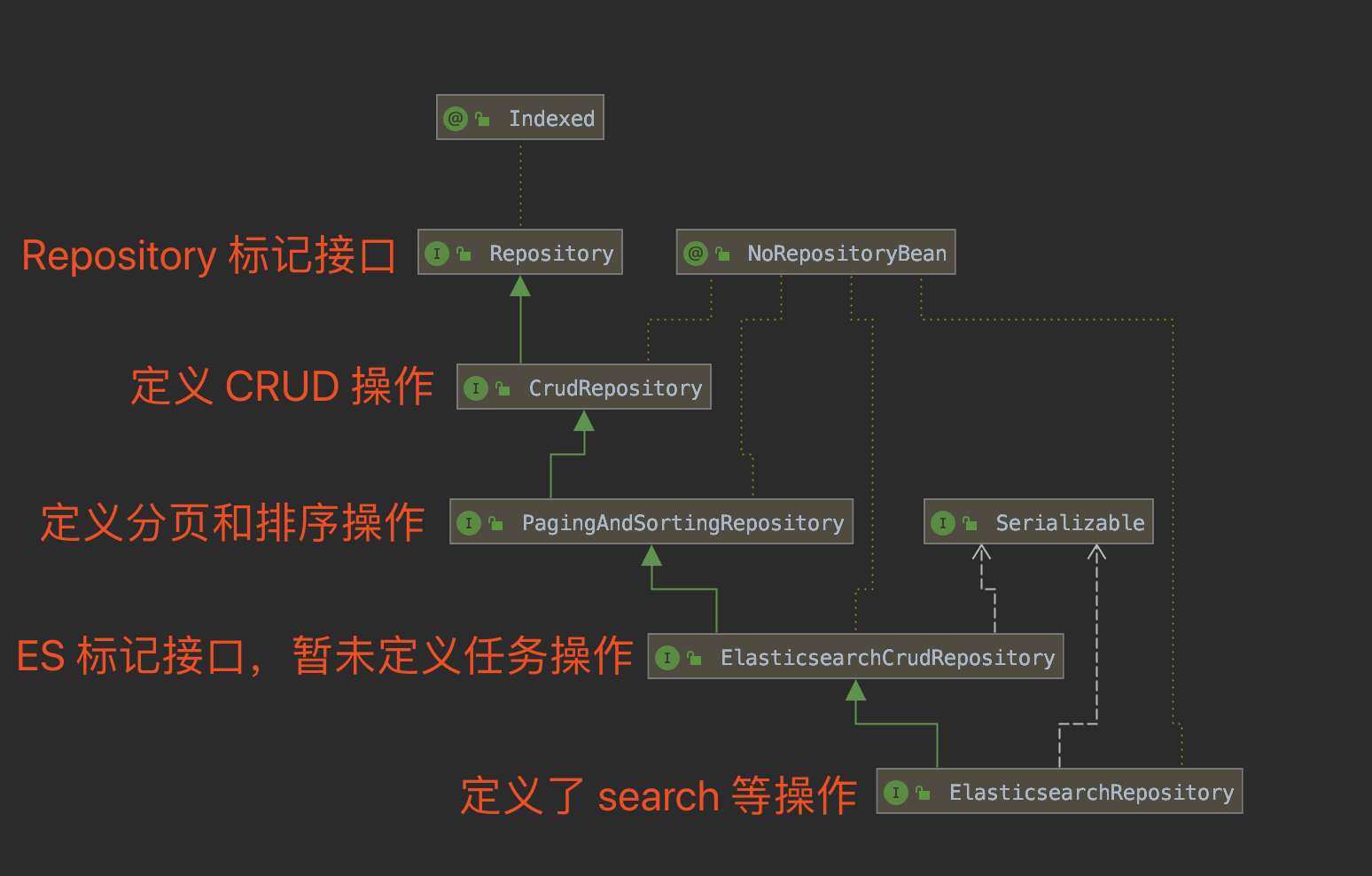
艿艿:如果胖友看过艿艿写的 《芋道 Spring Boot JPA 入门》 文章,会发现和 Spring Data JPA 的使用方式,基本一致。这就是 Spring Data 带给我们的好处,使用相同的 API ,统一访问不同的数据源。o( ̄▽ ̄)d 点赞。
2.6 简单测试
创建 ProductRepositoryTest 测试类,我们来测试一下简单的 ProductRepositoryTest 的每个操作。代码如下:
// ProductRepositoryTest.JAVA
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class ProductRepositoryTest {
@Autowired
private ProductRepository productRepository;
@Test // 插入一条记录
public void testInsert() {
ESProductDO product = new ESProductDO();
product.setId(1); // 一般 ES 的 ID 编号,使用 DB 数据对应的编号。这里,先写死
product.setName("芋道源码");
product.setSellPoint("愿半生编码,如一生老友");
product.setDescription("我只是一个描述");
product.setCid(1);
product.setCategoryName("技术");
productRepository.save(product);
}
// 这里要注意,如果使用 save 方法来更新的话,必须是全量字段,否则其它字段会被覆盖。
// 所以,这里仅仅是作为一个示例。
@Test // 更新一条记录
public void testUpdate() {
ESProductDO product = new ESProductDO();
product.setId(1);
product.setCid(2);
product.setCategoryName("技术-Java");
productRepository.save(product);
}
@Test // 根据 ID 编号,删除一条记录
public void testDelete() {
productRepository.deleteById(1);
}
@Test // 根据 ID 编号,查询一条记录
public void testSelectById() {
Optional<ESProductDO> userDO = productRepository.findById(1);
System.out.println(userDO.isPresent());
}
@Test // 根据 ID 编号数组,查询多条记录
public void testSelectByIds() {
Iterable<ESProductDO> users = productRepository.findAllById(Arrays.asList(1, 4));
users.forEach(System.out::println);
}
}具体的,胖友可以自己跑跑,妥妥的。
3. Spring Data Elasticsearch
示例代码对应仓库:lab-15-spring-data-elasticsearch 。
- ES 版本号:6.5.0
spring-boot-starter-data-elasticsearch:2.1.3.RELEASE
本小节,我们会使用 spring-boot-starter-data-elasticsearch 自动化配置 Spring Data Elasticsearch 主要配置。同时,编写相应的 Elasticsearch 的 CRUD 操作。
重点是,我们希望通过本小节,让胖友感受到,Spring Data Jest 和 Spring Data Elasticsearch 是基本一致的。
3.1 引入依赖
在 pom.xml 文件中,引入相关依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>lab-15-spring-data-elasticsearch</artifactId>
<dependencies>
<!-- 自动化配置 Spring Data Elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- 方便等会写单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>- 差异点,就是将依赖
spring-boot-starter-data-jest替换成spring-boot-starter-data-elasticsearch。
具体每个依赖的作用,胖友自己认真看下艿艿添加的所有注释噢。
3.2 Application
创建 Application.java 类,配置 @SpringBootApplication 注解即可。代码如下:
// Application.java
@SpringBootApplication
public class Application {
}- 差异点,在于无需排除 ElasticsearchAutoConfiguration 和 ElasticsearchDataAutoConfiguration 自动配置类,因为需要它们自动化配置 Spring Data Elasticsearch 。
3.3 配置文件
在 application.yml 中,添加 Jest 配置,如下:
spring:
data:
# Elasticsearch 配置项
elasticsearch:
cluster-name: elasticsearch # 集群名
cluster-nodes: 127.0.0.1:9300 # 集群节点- 差异点,将配置项
jest替换成elasticsearch。 - 我们使用本地的 ES 服务。默认情况下,ES transport 连接方式暴露的端口是 9300 。
3.4 ESProductDO
和 「2.4 ESProductDO」 一致。
3.5 ProductRepository
和 「3.5 ProductRepository」 一致。
3.6 简单测试
和 「3.6 简单测试」 一致。
😈 有没感受到,Spring Data Jest 和 Spring Data Elasticsearch 是基本一致的。
4. 基于方法名查询
示例代码对应仓库:lab-15-spring-data-jest 。
- ES 版本号:6.5.0
spring-boot-starter-data-jest:3.2.5.RELEASE
在 《芋道 Spring Boot JPA 入门》 文章的「4. 基于方法名查询」小节中,我们已经提到:
在 Spring Data 中,支持根据方法名作生成对应的查询(
WHERE)条件,进一步进化我们使用 JPA ,具体是方法名以findBy、existsBy、countBy、deleteBy开头,后面跟具体的条件。具体的规则,在 《Spring Data JPA ------ Query Creation》 文档中,已经详细提供。如下:
| 关键字 | 方法示例 | JPQL snippet |
|---|---|---|
And | findByLastnameAndFirstname | ... where x.lastname = ?1 and x.firstname = ?2 |
Or | findByLastnameOrFirstname | ... where x.lastname = ?1 or x.firstname = ?2 |
Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | ... where x.firstname = ?1 |
Between | findByStartDateBetween | ... where x.startDate between ?1 and ?2 |
LessThan | findByAgeLessThan | ... where x.age < ?1 |
LessThanEqual | findByAgeLessThanEqual | ... where x.age <= ?1 |
GreaterThan | findByAgeGreaterThan | ... where x.age > ?1 |
GreaterThanEqual | findByAgeGreaterThanEqual | ... where x.age >= ?1 |
After | findByStartDateAfter | ... where x.startDate > ?1 |
Before | findByStartDateBefore | ... where x.startDate < ?1 |
IsNull, Null | findByAge(Is)Null | ... where x.age is null |
IsNotNull, NotNull | findByAge(Is)NotNull | ... where x.age not null |
Like | findByFirstnameLike | ... where x.firstname like ?1 |
NotLike | findByFirstnameNotLike | ... where x.firstname not like ?1 |
StartingWith | findByFirstnameStartingWith | ... where x.firstname like ?1 (parameter bound with appended %) |
EndingWith | findByFirstnameEndingWith | ... where x.firstname like ?1 (parameter bound with prepended %) |
Containing | findByFirstnameContaining | ... where x.firstname like ?1 (parameter bound wrapped in %) |
OrderBy | findByAgeOrderByLastnameDesc | ... where x.age = ?1 order by x.lastname desc |
Not | findByLastnameNot | ... where x.lastname <> ?1 |
In | findByAgeIn(Collection ages) | ... where x.age in ?1 |
NotIn | findByAgeNotIn(Collection ages) | ... where x.age not in ?1 |
True | findByActiveTrue() | ... where x.active = true |
False | findByActiveFalse() | ... where x.active = false |
IgnoreCase | findByFirstnameIgnoreCase | ... where UPPER(x.firstame) = UPPER(?1) |
- 注意,如果我们有排序需求,可以使用
OrderBy关键字。
下面,我们来编写一个简单的示例。
艿艿:IDEA 牛逼,提供的插件已经能够自动提示上述关键字。太强了~
因为 Spring Data Elasticsearch 和 Spring Data Jest 也是 Spring Data 体系中的一员,所以也能享受到基于方法名查询的福利。所以,我们在本小节中,我们也来尝试下。
我们会在 「2. Spring Data Jest」 的示例代码对应仓库 lab-15-spring-data-jest 的基础上,进行本小节的示例。
4.1 ProductRepository02
在 cn.iocoder.springboot.lab15.springdatajest.repository 包路径下,创建 UserRepository02 接口。代码如下:
// ProductRepository02.java
public interface ProductRepository02 extends ElasticsearchRepository<ESProductDO, Integer> {
ESProductDO findByName(String name);
Page<ESProductDO> findByNameLike(String name, Pageable pageable);
}- 对于分页操作,需要使用到 Pageable 参数,需要作为方法的最后一个参数。
4.2 简单测试
创建 UserRepository02Test 测试类,我们来测试一下简单的 UserRepository02Test 的每个操作。代码如下:
// UserRepository02Test.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class ProductRepository02Test {
@Autowired
private ProductRepository02 productRepository;
@Test // 根据名字获得一条记录
public void testFindByName() {
ESProductDO product = productRepository.findByName("芋道源码");
System.out.println(product);
}
@Test // 使用 name 模糊查询,分页返回结果
public void testFindByNameLike() {
// 根据情况,是否要制造测试数据
if (true) {
testInsert();
}
// 创建排序条件
Sort sort = new Sort(Sort.Direction.DESC, "id"); // ID 倒序
// 创建分页条件。
Pageable pageable = PageRequest.of(0, 10, sort);
// 执行分页操作
Page<ESProductDO> page = productRepository.findByNameLike("芋道", pageable);
// 打印
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
}
/**
* 为了给分页制造一点数据
*/
private void testInsert() {
for (int i = 1; i <= 100; i++) {
ESProductDO product = new ESProductDO();
product.setId(i); // 一般 ES 的 ID 编号,使用 DB 数据对应的编号。这里,先写死
product.setName("芋道源码:" + i);
product.setSellPoint("愿半生编码,如一生老友");
product.setDescription("我只是一个描述");
product.setCid(1);
product.setCategoryName("技术");
productRepository.save(product);
}
}
}5. 复杂查询
在一些业务场景下,我们需要编写相对复杂的查询,例如说类似京东 https://search.jd.com/Search?keyword=华为手机 搜索功能,需要支持关键字、分类、品牌等等,并且可以按照综合、销量等等升降序排序,那么我们就无法在上面看到的 Spring Data Repository 提供的简单的查询方法,而需要使用到 ElasticsearchRepository 的 search 方法,代码如下:
// ElasticsearchRepository.java
// 省略非 search 方法
Page<T> search(QueryBuilder query, Pageable pageable);
Page<T> search(SearchQuery searchQuery);
Page<T> searchSimilar(T entity, String[] fields, Pageable pageable);此时,我们就需要使用 QueryBuilder 和 SearchQuery 构建相对复杂的搜索和排序条件。所以,我们继续在 「2. Spring Data Jest」 的示例代码对应仓库 lab-15-spring-data-jest 的基础上,进行本小节的示例,实现一个简单的商品搜索功能。
5.1 ProductRepository03
在 cn.iocoder.springboot.lab15.springdatajest.repository 包路径下,创建 ProductRepository03 接口。代码如下:
// ProductRepository03.java
public interface ProductRepository03 extends ElasticsearchRepository<ESProductDO, Integer> {
default Page<ESProductDO> search(Integer cid, String keyword, Pageable pageable) {
// <1> 创建 NativeSearchQueryBuilder 对象
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// <2.1> 筛选条件 cid
if (cid != null) {
nativeSearchQueryBuilder.withFilter(QueryBuilders.termQuery("cid", cid));
}
// <2.2> 筛选
if (StringUtils.hasText(keyword)) {
FunctionScoreQueryBuilder.FilterFunctionBuilder[] functions = { // TODO 芋艿,分值随便打的
new FunctionScoreQueryBuilder.FilterFunctionBuilder(matchQuery("name", keyword),
ScoreFunctionBuilders.weightFactorFunction(10)),
new FunctionScoreQueryBuilder.FilterFunctionBuilder(matchQuery("sellPoint", keyword),
ScoreFunctionBuilders.weightFactorFunction(2)),
new FunctionScoreQueryBuilder.FilterFunctionBuilder(matchQuery("categoryName", keyword),
ScoreFunctionBuilders.weightFactorFunction(3)),
// new FunctionScoreQueryBuilder.FilterFunctionBuilder(matchQuery("description", keyword),
// ScoreFunctionBuilders.weightFactorFunction(2)), // TODO 芋艿,目前这么做,如果商品描述很长,在按照价格降序,会命中超级多的关键字。
};
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(functions)
.scoreMode(FunctionScoreQuery.ScoreMode.SUM) // 求和
.setMinScore(2F); // TODO 芋艿,需要考虑下 score
nativeSearchQueryBuilder.withQuery(functionScoreQueryBuilder);
}
// 排序
if (StringUtils.hasText(keyword)) { // <3.1> 关键字,使用打分
nativeSearchQueryBuilder.withSort(SortBuilders.scoreSort().order(SortOrder.DESC));
} else if (pageable.getSort().isSorted()) { // <3.2> 有排序,则进行拼接
pageable.getSort().get().forEach(sortField -> nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort(sortField.getProperty())
.order(sortField.getDirection().isAscending() ? SortOrder.ASC : SortOrder.DESC)));
} else { // <3.3> 无排序,则按照 ID 倒序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC));
}
// <4> 分页
nativeSearchQueryBuilder.withPageable(PageRequest.of(pageable.getPageNumber(), pageable.getPageSize())); // 避免
// <5> 执行查询
return search(nativeSearchQueryBuilder.build());
}
}- 使用 QueryBuilder 和 SearchQuery 构建相对复杂的搜索和排序条件,我们可以放在 Service 层,也可以放在 Repository 层。艿艿个人的偏好放在 Repository 层。
- 主要原因是,尽量避免数据层的操作暴露在 Service 层。
- 缺点呢,就像我们这里看到的,有点业务逻辑就到了 Repository 层。
- 😈 有舍有得,看个人喜好。翻了一些开源项目,放在 Service 或 Repository 层的都有。
- 简单来说下这个方法的整体逻辑,根据商品分类编号 + 关键字,检索相应的商品,分页返回结果。
<1>处,创建 NativeSearchQueryBuilder 对象。- 筛选条件
<2.1>处,如果有分类编号cid,则进行筛选。<2.2>处,如果有关键字keyword,则按照name10 分、sellPoint2 分、categoryName3 分,计算求和,筛选至少满足 2 分。
- 排序条件
<3.1>处,如果有关键字,则按照打分结果降序。<3.2>处,如果有排序条件,则按照该排序即可。<3.3>处,如果无排序条件,则按照 ID 编号降序。
- 分页条件
<4>处,创建新的 PageRequest 对象,避免pageable里原有的排序条件。
- 执行搜索
<5>处,调用#search(SearchQuery searchQuery)方法,执行 Elasticsearch 搜索。
5.2 ProductRepository03Test
创建 ProductRepository03Test 测试类,我们来测试一下简单的 UserRepository03Test 的每个操作。代码如下:
// ProductRepository03Test.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class ProductRepository03Test {
@Autowired
private ProductRepository03 productRepository;
@Test
public void testSearch() {
// 查找分类为 1 + 指定关键字,并且按照 id 升序
Page<ESProductDO> page = productRepository.search(1, "技术",
PageRequest.of(0, 5, Sort.Direction.ASC, "id"));
System.out.println(page.getTotalPages());
// 查找分类为 1 ,并且按照 id 升序
page = productRepository.search(1, null,
PageRequest.of(0, 5, Sort.Direction.ASC, "id"));
System.out.println(page.getTotalPages());
}
}具体的,胖友可以自己跑跑,妥妥的。
6. ElasticsearchTemplate
在 Spring Data Elasticsearch 中,有一个 ElasticsearchTemplate 类,提供了 Elasticsearch 操作模板,方便我们操作 Elasticsearch 。
😈 要注意,这是 Spring Data Elasticsearch 独有,而 Spring Data Jest 没有的一个类。
咳咳咳,当艿艿写完这篇博客后,突然发现,Spring Data Jest 有一个 JestElasticsearchTemplate 类,和 ElasticsearchTemplate 是对等的。
也因此,我们继续在 「3. Spring Data Elasticsearch」 的示例代码对应仓库 lab-15-spring-data-elasticsearch 的基础上,进行本小节的示例,实现一个商品搜索条件返回的功能。
6.1 ProductConditionBO
在 cn.iocoder.springboot.lab15.springdataelasticsearch.bo 包路径下,创建 ProductConditionBO 类,商品搜索条件 BO ,代码如下:
// ProductConditionBO.java
public class ProductConditionBO {
/**
* 商品分类数组
*/
private List<Category> categories;
public static class Category {
/**
* 分类编号
*/
private Integer id;
/**
* 分类名称
*/
private String name;
// ... 省略 setting/getting 方法
}
// ... 省略 setting/getting 方法
}6.2 简单示例
创建 ProductRepository04Test 测试类,我们来测试一下简单的 ProductRepository04Test 的每个操作。代码如下:
// ProductRepository04Test.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class ProductRepository04Test {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void test() {
// <1> 创建 ES 搜索条件
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder()
.withIndices("product");;
// <2> 筛选
nativeSearchQueryBuilder.withQuery(QueryBuilders.multiMatchQuery("芋道",
"name", "sellPoint", "categoryName"));
// <3> 聚合
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("cids").field("cid")); // 商品分类
// <4> 执行查询
ProductConditionBO condition = elasticsearchTemplate.query(nativeSearchQueryBuilder.build(), response -> {
ProductConditionBO result = new ProductConditionBO();
// categoryIds 聚合
Aggregation categoryIdsAggregation = response.getAggregations().get("cids");
if (categoryIdsAggregation != null) {
result.setCategories(new ArrayList<>());
for (LongTerms.Bucket bucket : (((LongTerms) categoryIdsAggregation).getBuckets())) {
result.getCategories().add(new ProductConditionBO.Category().setId(bucket.getKeyAsNumber().intValue()));
}
}
// 返回结果
return result;
});
// <5> 后续遍历 condition.categories 数组,查询商品分类,设置商品分类名。
System.out.println();
}
}- 简单来说下这个方法的整体逻辑,根据关键字检索
name、sellPoint、categoryName字段,聚合cid返回。 <1>处,创建 NativeSearchQueryBuilder 对象,并设置查询的索引是product,即 ESProductDO 类的对应的索引。- 筛选条件
<2>处,根据关键字检索name、sellPoint、categoryName字段。此处,我们使用的关键字是"芋道"。
- 聚合
<3>处,将商品分类编号cid聚合成cids返回。- 如果 ESProductDO 上有品牌编号,我们可以多在聚合一个品牌编号返回。
- 执行搜索
<4>处,执行查询,解析聚合结果,设置回 ProductConditionBO 中。
<5>处,后续遍历condition.categories数组,查询商品分类,设置商品分类名。
可能胖友会有疑惑?Spring Data Jest 没有 ElasticsearchTemplate 类,岂不是不能实现当前示例么?答案是否定的,我们回过头看 「5. 复杂查询」 。对于 Spring Data Jest 来说,可以通过 ElasticsearchRepository 提供的 search 方法,实现聚合操作的功能。当然,Spring Data Elasticsearch 也可以。
所以呢,绝大多数情况下,我们并不会直接使用 ElasticsearchTemplate 类。
通过写这篇文章,艿艿自己也查了一些资料,终于把 Elasticsearch 客户端的情况理顺了。😈 当然,也推荐几篇艿艿觉得不错的 Elasticsearch 文章:
- 《图解 Elasticsearch 原理》
- 《全文搜索引擎选 ElasticSearch 还是 Solr?》
- 《别再说你不会 ElasticSearch 调优了,都给你整理好了》
- 《Elasticsearch 如何做到亿级数据查询毫秒级返回?》
- 《日均 5 亿查询量的京东订单中心,为什么舍 MySQL 用 ES ?》
另外,在推荐一个 Chrome ElasticSearch Head 插件,可用于监控 Elasticsearch 状态的客户端,提供数据可视化、执行增删改查操作等等功能。
来源:https://blog.csdn.net/weixin_42073629/article/details/105826899