55.Spring Boot 监控平台 Prometheus + Grafana 入门
55.Spring Boot 监控平台 Prometheus + Grafana 入门
1. 概述
在《芋道 Spring Boot 监控工具 Admin 入门》文章中,我们学习了如何使用 Spring Boot Admin 作为 Spring Boot 应用的监控和管理工具。
友情提示:对于本文来说,即使胖友未阅读过《芋道 Spring Boot 监控工具 Admin 入门》文章,也毫无影响,不要慌~
不过正如我们在文末所说,Spring Boot Admin 是个轻量级 的监控工具,默认无法提供历史监控数据的查询,这对我们在排查问题时,可能不是特别不便利。
所以,本文我们就一起来,使用 Prometheus + Grafana 组件,搭建统一的监控平台。并且,来实现一个对 Spring Boot 应用监控的示例。
在阅读本文之前,胖友先去阅读下艿艿写的《芋道 Prometheus + Grafana + Alertmanager 极简入门》文章,先把 Prometheus、Grafana、Alertmanager 三个组件给搭建起来。同时在搭建的过程中,会对这三者有个直观的感受和认识。
2. Spring Boot 应用
示例代码对应仓库:lab-36-prometheus-demo 。
在《Spring Boot 监控端点 Actuator 入门》中,我们学习了 Spring Boot Actuator 端点,可以提供 HTTP 接口,获取应用的监控数据,特别是「6. metrics 端点」 可以提供 Prometheus 需要的采集 Metrics 指标数据。
但是,Actuator metrics 端点提供的返回数据格式,并不符合 Prometheus 采集所需的格式。❓这可咋整呢❓所幸,Actuator 在 Spring Boot 2.X 版本后,基于 Micrometer 来实现,而 Micrometer 的 micrometer-registry-prometheus 库,提供了对 Prometheus 的支持。
友情提示:对于本文来说,即使胖友未阅读过《Spring Boot 监控端点 Actuator 入门》文章,也毫无影响,不要慌~
下面,我们来搭建一个可以被 Prometheus 采集 Metrics 指标数据的 Spring Boot 应用实例。
2.1 引入依赖
在 pom.xml 文件中,引入相关依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>lab-36-prometheus-demo</artifactId>
<dependencies>
<!-- 实现对 Spring MVC 的自动化配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 实现对 Actuator 的自动化配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- Micrometer 对 Prometheus 的支持 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
</dependencies>
</project>- 具体每个依赖的作用,胖友自己认真看下艿艿添加的所有注释噢。
- 另外,
spring-boot-starter-web依赖并不是必须的,仅仅是为了保证 Spring Boot 应用启动后持续运行。
在引入 micrometer-registry-prometheus 库后,Actuator 提供的 PrometheusMetricsExportAutoConfiguration.PrometheusScrapeEndpointConfiguration 自动化配置类,创建 Actuator 实现的 PrometheusScrapeEndpoint 。
PrometheusScrapeEndpoint 对应 prometheus 端点。后续,Prometheus Server 通过请求该应用的 GET /actuator/prometheus 接口,即可完成应用的 Metrics 指标数据的爬取。
2.2 配置文件
在 application.yml 中,添加 Actuator 配置,如下:
spring:
application:
name: demo-application # 应用名
management:
endpoints:
# Actuator HTTP 配置项,对应 WebEndpointProperties 配置类
web:
exposure:
include: '*' # 需要开放的端点。默认值只打开 health 和 info 两个端点。通过设置 * ,可以开放所有端点。
metrics:
tags: # 通用标签
application: ${spring.application.name}- 配置项
spring.application.name,设置应用名。 - 配置项
management.endpoints.web.exposure.include = *,设置 Actuator 暴露所有端点。这样,prometheus端点也能被暴露出来。 - 【重要】配置项
management.metrics.tags,设置 Metrics 通用标签。这里,我们配置了一个通过用标签键为application,值为${spring.application.name}。我们来试着想下,应用 A 和应用 B 都有相同的 Metrics 名,那么如果我们需要去区分它们,则需要通过给 Metrics 打上不同的标签来区分,而一般情况下,我们会选择application作为标签。如果胖友有使用过 Prometheus + Grafana 来做监控报表,会发现也是推荐这么实践的。
2.3 Application
创建 Application.java 类,配置 @SpringBootApplication 注解即可。代码如下:
// Application.java
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}2.4 简单测试
执行 Application#main(String[] args) 方法,启动应用。
打开浏览器,访问 http://127.0.0.1:8080/actuator/prometheus 地址,获得应用的 Prometheus 所需的格式的 Metrics 指标数据。响应结果如下图:
- 每个 Metrics 指标的定义,胖友看看其上的英文注释,并不难懂。
- 每个 Metrics 指标的格式,
[指标名][指标标签 JSON 串] [指标值]。
3. 接入 Prometheus
在「2. Spring Boot 应用」中,我们已经搭建了一个 Spring Boot 应用,并提供 GET /actuator/prometheus 接口。而本小节,我们来配置一个 Prometheus Job ,让 Prometheus Server 通过该接口,进行该应用的 Metrics 指标数据的采集。
3.1 配置文件
修改 prometheus.yml 配置文件,增加抓取「2. Spring Boot 应用」的 Job 。配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'demo-application'
# 采集地址
metrics_path: '/actuator/prometheus'
# 目标服务器
static_configs:
- targets: ['127.0.0.1:8080']- 在
scrape_configs配置项下,已经设置了一个名字为demo-application的 Job 。该 Job 的抓取目标,通过targets来设置,就是「2. Spring Boot 应用」的地址。 - 更多 Prometheus 的配置说明,可见《Prometheus 文档 ------ CONFIGURATION》文档。
3.2 启动 Prometheus 服务
如果胖友此时并未启动 Prometheus 服务,则可执行 nohup ./prometheus --config.file=prometheus.yml & 命令,启动 Prometheus 服务。
如果胖友此时已经启动 Prometheus 服务,则需要让 Prometheus 重新加载配置。命令行操作如下:
# 获得 Prometheus 服务的进程编号
$ ps -ef | grep 'prometheus --config.file=prometheus.yml'
501 80562 1 0 12:43AM ?? 0:53.99 ./prometheus --config.file=prometheus.yml
# 通过 kill -HUP pid 的方式,让 Prometheus 重新加载配置
$ kill -HUP 80562- 另外,在《如何热加载更新配置?》文章,推荐建议使用
curl -X POST http://IP/-/reload来重新加载配置。😈 这里,艿艿主要感觉胖友可能并未开启--web.enable-lifecycle参数,所以就不采用这种方式。
此时,我们使用浏览器,访问 http://127.0.0.1:9090/targets 地址,可以看到 Prometheus Job 抓取的所有目标。如下图所示:
- 我们的「2. Spring Boot 应用」的 Metrics 指标数据,被 Prometheus Server 成功抓取。
3.3 简单使用
使用浏览器,访问 http://127.0.0.1:9090/ 地址,会自动跳转到 http://127.0.0.1:9090/graph/ 地址,Prometheus 自带的图表功能。如下图所示:
点击黄圈「insert metrics at cursor」下拉框,选择 jvm_buffer_count_buffers 这个 Metrics 指标,然后点击「Execute」按钮,执行查询该指标的数据。结果如下图:
- 可以看到 5 条记录。
instance内置 标签:代表来自哪个抓取目标。这里,就是「2. Spring Boot 应用」。job内置 标签:代表来自哪个 Job。这里,就是我们在「3.2 配置文件」中,新增的 Job。application自定义 标签:代表来自哪个应用。这里,就是我们在「2.2 配置文件」中配置项management.metrics.tags所设置的application = demo-application。id自定义 标签:是jvm_buffer_count_buffers指标所独有 ,定义了"direct"、"mapped"两种值。
点击「Graph」Tab 选项,切换到图视图。此时,我们可以看到近一小时的折线图。如下:
虽然说,Prometheus 自带了 📈 图表功能,不过还是比较基础的。因此,我们更多的使用 Grafana 来制作监控仪表盘。
4. 接入 Grafana
在「3. 接入 Prometheus」中,我们已经使用 Prometheus Server 采集了「2. Spring Boot 应用」的 Metrics 指标数据。所以在本小节中,我们来使用 Grafana 来制作 Spring Boot 应用的 Dashboard 。
在 Dashboard 市场 中,提供了两个适合 Spring Boot 应用的 Dashboard:
😈 完美的可以偷懒,下面我们来导入 Grafana 试试,尝试使用这两个 Dashboard。
4.1 Spring Boot Statistics
目前 Spring Boot Statistics,存在一定的 BUG 。不过艿艿又翻下了,发现可以使用 Spring Boot 2.1 Statistics 作为替代。猜测是进行了一定的修复。
Grafana 导入 Spring Boot 2.1 Statistics,效果如下图所示:
4.2 JVM (Micrometer)
Grafana 导入 JVM (Micrometer),效果如下图所示:
5. 接入 Alertmanager
本小节,我们在《Prometheus + Grafana + Alertmanager 极简入门》的「7. Alertmanager 搭建」小节的基础上,实现对「2. Spring Boot 应用」的监控告警。
监控告警的具体条件是,至少有一个运行的 Spring Boot 应用。
5.1 配置 Prometheus 告警规则
① 下面,我们来配置一个 Prometheus 的告警规则示例。命令行操作如下:
# 查看当前目录,主要目的是告诉胖友,到 Prometheus 所在目录哈
$ pwd
/Users/yunai/monitoring/alertmanager-0.20.0.darwin-amd64
# 创建 demo.yml 示例告警规则文件
$ vi rules/demo-application.yml具体的 rules/demo-application.yml 规则如下:
groups:
- name: demo-application-group
rules:
- alert: demo-application-rule-01
expr: up{job="demo-application"} < 1
for: 10s
labels:
severity: critical
annotations:
summary: "{{$labels.job}}: 应用都挂了"
description: "赶紧解决啊!!!"- 这里,我们配置了一条告警规则,如果名字为
"demo-applicatio"的 Job ,可抓取的处于 UP 状态的目标实例小于 1 ,则触发告警。 - 我们在「2. Spring Boot 应用」中,只搭建了一个 Spring Boot 应用节点。如果在「5.2 简单测试」中,我们关闭该应用节点,则会触发该规则的告警。
② 需要让 Prometheus 重新加载配置。命令行操作如下:
# 获得 Prometheus 服务的进程编号
$ ps -ef | grep 'prometheus --config.file=prometheus.yml'
501 80562 1 0 12:43AM ?? 0:53.99 ./prometheus --config.file=prometheus.yml
# 通过 kill -HUP pid 的方式,让 Prometheus 重新加载配置
$ kill -HUP 80562③ 使用浏览器,访问 http://127.0.0.1:9093/ 地址,进入 Prometheus 首页。点击「Status」菜单,选择「Rules」选项,可以看到所有的 Prometheus 告警规则。如下图所示:
5.2 简单测试
① 手动关闭搭建的 Spring Boot 应用节点,因为咱要触发告警。
② 使用浏览器,访问 http://127.0.0.1:9090/ 地址,进入 Prometheus 首页。点击「Alerts」菜单,可以看到目前的告警状态。如下图所示: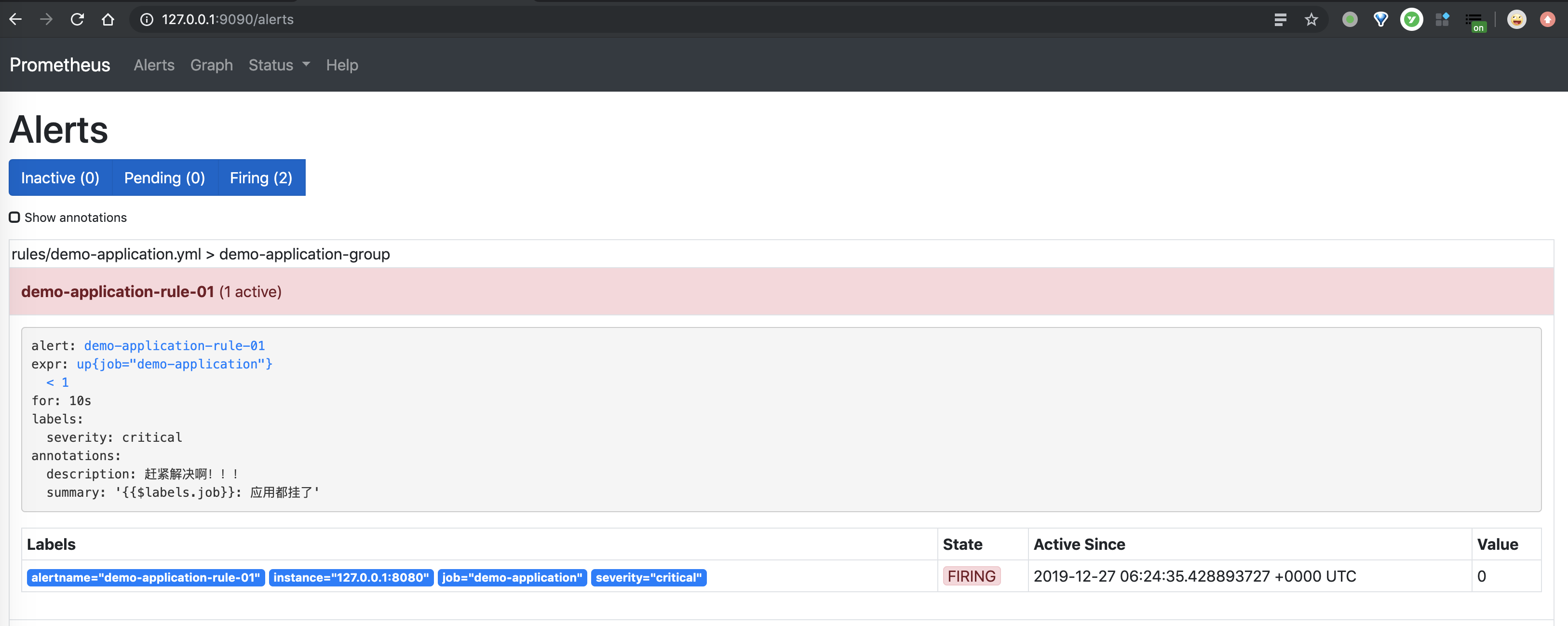
如果胖友发现该告警规则还未处于「FIRING」状态,可以在耐心等待一会,然后进行刷新。因为,我们配置的告警规则,需要满足 10 秒(通过 for = 10s 配置)。
③ 打开接收告警的邮箱,我们应该会收到告警邮件。如下图所示:
④ 打开钉钉,我们应该会收到机器人的告警。如下图所示:
6. Spring Boot 自定义 Metrics 指标
在《Spring Boot 监控端点 Actuator 入门》的「6.2 自定义指标」小节中,我们提供了如何自定义 Spring Boot 自定义 Metrics 指标的示例。
推荐胖友抽 10 分钟左右,简单了解一波,还是蛮有必要的。
来源:https://blog.csdn.net/weixin_42073629/article/details/106772030